Big Data e Small Data: la chiave è l’integrazione
Big Data
Con il termine Big Data si intende una raccolta di dati molto estesa, generati da persone o da macchine e che, tramite tecniche e metodologie avanzate, vengono elaborati all’interno di database. Ad aiutarci nella definizione di Big Data, ci ha pensato Doug Laney che, nel 2001, definì un modello descrittivo della nuova tipologia di dati che si stava sviluppando ai tempi: il “Modello delle 3V”, ossia Volume, Velocità e Varietà.
Il modello delle 3V
Il volume dei dati globali cresce sempre di più e sempre più velocemente, pertanto risulta complesso stabilire una soglia oltre la quale si possa parlare di Big Data. Attualmente, il Volume considerato “grande” è quello che eccede i 50 Terabyte. Altra caratteristica è quella della Velocità, intesa come rapidità nella raccolta dei dati. Il termine potrebbe trarre in inganno e far pensare alla velocità di download, ma così non è. In particolare, ci si riferisce alla capacità di raccoglierli in tempo reale, come accade con i registratori di cassa, sensori o social media. Infine, i dati devono essere vari, nel senso che devono essere in grado di rappresentare la realtà in tutta la sua complessità e dimensioni. Pertanto, con la Varietà si fa riferimento alle differenti tipologie di dati disponibili, strutturati e non e interni alle aziende o acquisiti esternamente.
Il modello delle 5V
Il paradigma delle 3V nel tempo si è modificato, passando ad oggi alle “5V dei Big Data“, con l’introduzione di due nuovi requisiti: Veridicità e Variabilità. Nel primo caso, i dati devono essere affidabili e rappresentare in maniera coerente la realtà. È importante, quindi, che i dati siano integri e che non siano falsati da una non corretta rilevazione. Invece, in merito alla Variabilità, si richiama il contesto di riferimento dei dati stessi. Questo perché, come già ribadito, i dati sono raccolti in molteplici dimensioni ed è bene che siano in grado di rappresentarle in maniera univoca.
Infine, forse è bene citare anche quella che è considerata la “sesta V”, ossia il Valore: i dati devono essere in grado di generare valore e informazioni significative, e il solo fatto di possedere un ingente volume di dati non significa che questi siano poi in grado di creare nuova conoscenza.

Small Data
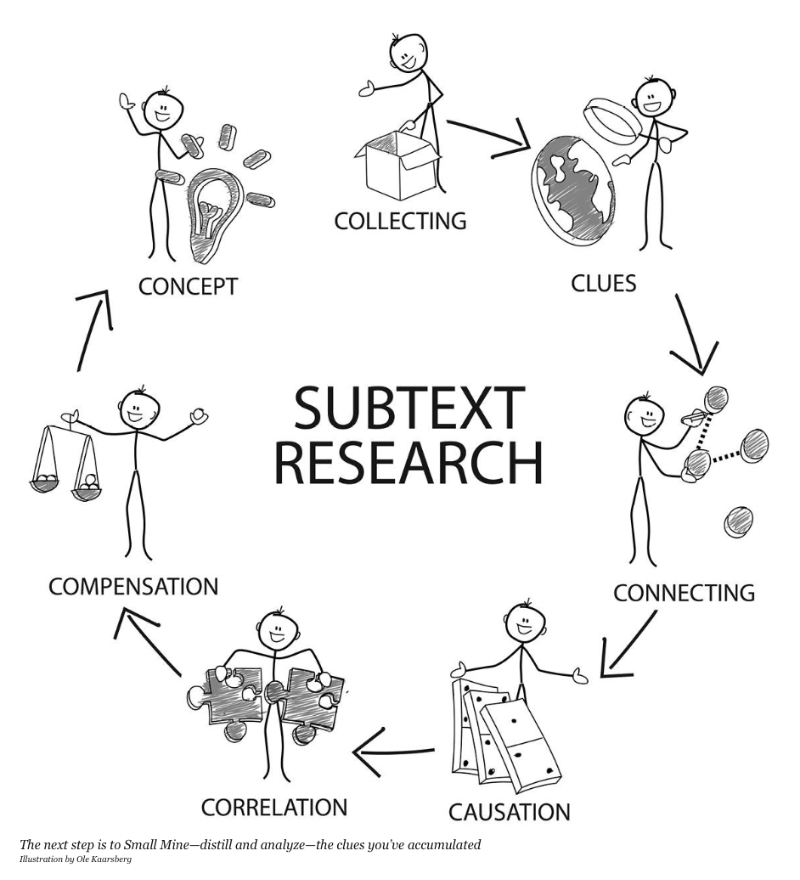
Gli Small Data sono dati in un volume e un formato che consente loro di essere accessibili e fruibili da un umano con facilità. Anche per gli Small Data esiste un modello il “Modello delle 7C”, sviluppato da Martin Lindstrom, il principale teorico di questo tema. I sette passaggi previsti da Lindstorm sono:
1.Collezionare (Collecting): in questa prima fase, l’obiettivo è quello di raccogliere quanti più dati possibile, secondo diverse prospettive;
2.Indizi (Clues): fa riferimento alla capacità di cogliere gli indizi, per comprendere al meglio la realtà che si osserva e le emozioni ad essa collegate;
3.Connettersi (Connecting): trovare i punti in comune tra le due fasi precedenti e individuare una strada ben precisa;
4.Correlazione (Correlation): arrivare al momento preciso in cui è apparso per la prima volta il comportamento o l’emozione individuata in precedenza;
5.Causa (Causation): cercare le relazioni causa-effetto;
6.Compesazione (Compensation): comprendere qual è il desiderio non soddisfatto e qual è il miglior modo per soddisfarlo;
7.Concetto (Concept): mettere in luce l’idea aziendale che fornisce risposta al bisogno identificato.
Il processo di raccolta, analisi e creazione di un’idea valida e riproducibile degli Small Data mette in luce gli elementi fondamentali da seguire: curiosità, intuizione, osservazione e indagine. Gli Small Data, infatti, sono dati ben strutturati che sono pensati proprio per fornire informazioni specifiche, basate sull’osservazione di dettagli. Secondo Lindstrom, il modo migliore per comprendere il reale comportamento delle persone è quello di osservare la loro quotidianità. A livello aziendale, come abbiamo potuto osservare, si traduce nell’identificazione di strategie basate sull’individuazione dei bisogni specifici degli utenti/consumatori.
BIG DATA VS SMALL DATA?
La differenza principale tra le due tipologie risiede sicuramente nella componente umana e emozionale che appartiene agli Small Data e non ai Big Data, più orientati ai database, agli algoritmi e a tutto ciò che ha a che fare con l’aspetto tecnologico. Anche la loro elaborazione comporta delle differenze: gli Small Data sono più semplici da interpretare, mentre i Big Data per essere raccolti e manipolati necessitano di competenze specifiche e risultano di più difficile gestione. Tuttavia, non esiste una tipologia prevalente sull’altra, ma anzi, bisognerebbe trovare il modo di integrarli al fine di ottenere vantaggi da entrambi. Infatti, tramite una loro contaminazione è possibile sfruttarli al meglio per raggiungere un unico obiettivo: la soddisfazione di determinati bisogni e l’individuazione della migliore strategia per farlo. È possibile, infatti, processare una prima raccolta e analisi dei Big Data per elaborare informazioni, da approfondire poi nel dettaglio con gli Small Data.
In un processo che li coinvolge entrambi, per esempio, si potrebbero usare i Big Data per raccogliere dati, in grande misura creando un contesto e una panoramica generica e usare questi risultati per combinarli con gli Small Data, aggiungendo l’aspetto emozionale che permette di cogliere gli insight più significativi. Gli Small Data, così facendo, diventano la chiave di lettura dei Big Data.